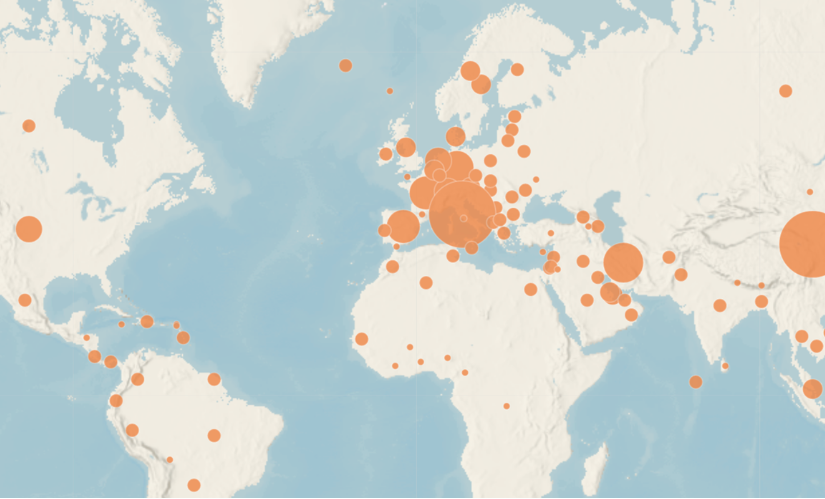
Mapa del estado de contagios por coronavirus en España actualizado a 14 de marzo de 2020, datos por comunidades autónomas (datos distribuidos por el Ministerio de Sanidad de España)
Información suministrada por la OMS (Organización Mundial de la Salud) sobre el coronavirus
El COVID-19 es una enfermedad infecciosa causada por un nuevo virus (SARS-CoV-2) que no había sido detectado en humanos hasta la fecha y que se ha convertido en pandemia mundial a inicios de 2020. El virus causa una enfermedad respiratoria como la gripe (influenza) con diversos síntomas (tos, fiebre, etc.) que, en casos graves, puede producir una neumonía. Como medida de protección puede lavarse las manos regularmente y evitar tocarse la cara.
¿CÓMO SE PROPAGA?
El nuevo coronavirus se propaga principalmente por contacto directo (menos de 1 metro de distancia) con una persona infectada cuando tose o estornuda, o por contacto con sus gotículas respiratorias (saliva o secreciones nasales).
Síntomas
El COVID-19 se caracteriza por síntomas leves, como, secreciones nasales, dolor de garganta, tos y fiebre. La enfermedad puede ser más grave en algunas personas y provocar neumonía o dificultades respiratorias. Más raramente puede ser mortal. Las personas de edad avanzada y las personas con otras afecciones médicas (como asma, diabetes o cardiopatías) pueden ser más vulnerables y enfermar de gravedad.
Los signos y síntomas pueden ser: secreciones nasales, dolor de garganta, tos, fiebre o dificultad para respirar (en casos graves).
Prevención
Actualmente no existe vacuna para prevenir el COVID-19. Aunque varios laboratorios a nivel mundial trabajan a contrareloj para encontrar una vacuna.
Puede reducir el riesgo de infección con estos consejos:
- Lavándose las manos regularmente con agua y jabón o con desinfectante de manos a base de alcohol.
- Cubriéndose la nariz y la boca al toser y estornudar con un pañuelo de papel desechable o con la parte interna del codo.
- Evitando el contacto directo (1 metro) con cualquier persona con síntomas de resfriado o gripe.
Tratamientos
No existe ningún medicamento para prevenir o tratar la COVID-19. Algunos pacientes pueden necesitar tratamiento sintomático que les ayude a respirar.
Cuidados personales:
Si presenta síntomas leves, quédese en casa hasta recuperarse. Puede aliviar sus síntomas:
- descansando y durmiendo
- manteniéndose caliente
- bebiendo muchos líquidos
- utilizando humidificadores o tomando duchas calientes para aliviar el dolor de garganta y la tos
Tratamientos médicos:
Si presenta fiebre, tos y dificultad para respirar, busque inmediatamente atención médica. Llame con antelación a su proveedor de atención de salud e indíquele si recientemente ha viajado o estado en contacto con personas que hayan viajado.